

Background
Imagine running a healthcare organization that depends on one employee to manually reach out to over 200 patients every day in order to schedule, reschedule, and confirm hundreds of valuable appointments you would otherwise lose. Now imagine that same employee wants to retire. This is the exact scenario one of our customers found themselves in.
When we heard this story it became clear that Assort could provide incredible customer value by extending the agentic capabilities of our inbound patient access agent to an outbound product. At the time, Assort had just crossed 40M patient interactions (now 150m+!), so we were confident we could take our learnings from creating a successful inbound agent and apply them to a new frontier in proactive patient access.
Along the way, we were introduced to new engineering and product questions. How do you handle making eight thousand rescheduling calls before 8AM when a winter storm shuts down every clinic your customer owns that day? How do you ensure every patient scheduled in the next six months with a provider who's leaving the clinic is successfully rescheduled? How do you make sure patients pick up the phone when it's time for them to confirm their appointment? How do we help patients book preventative care? To meet our customer needs, we needed to design a system around four core requirements: the system needed to scale elastically to absorb sudden spikes to 100x the usual volume of concurrent calls, tolerate faults to guarantee every patient is reached regardless of upstream failures, provide a patient experience that encourages engagement rather than suspicion, and make real-time observability available for our customers so they can keep full control and gain insight into how their outreach performs.
Durable Orchestration
Our customer's employee was the sole orchestrator of outbound patient scheduling at her clinic, so she could easily keep track of who was picking up the phone, who called in to cancel an appointment, and when (or if) she failed to outreach at the appointed time. When something went wrong, she knew when to call again. In short, she made herself a highly available and fault tolerant orchestrator.
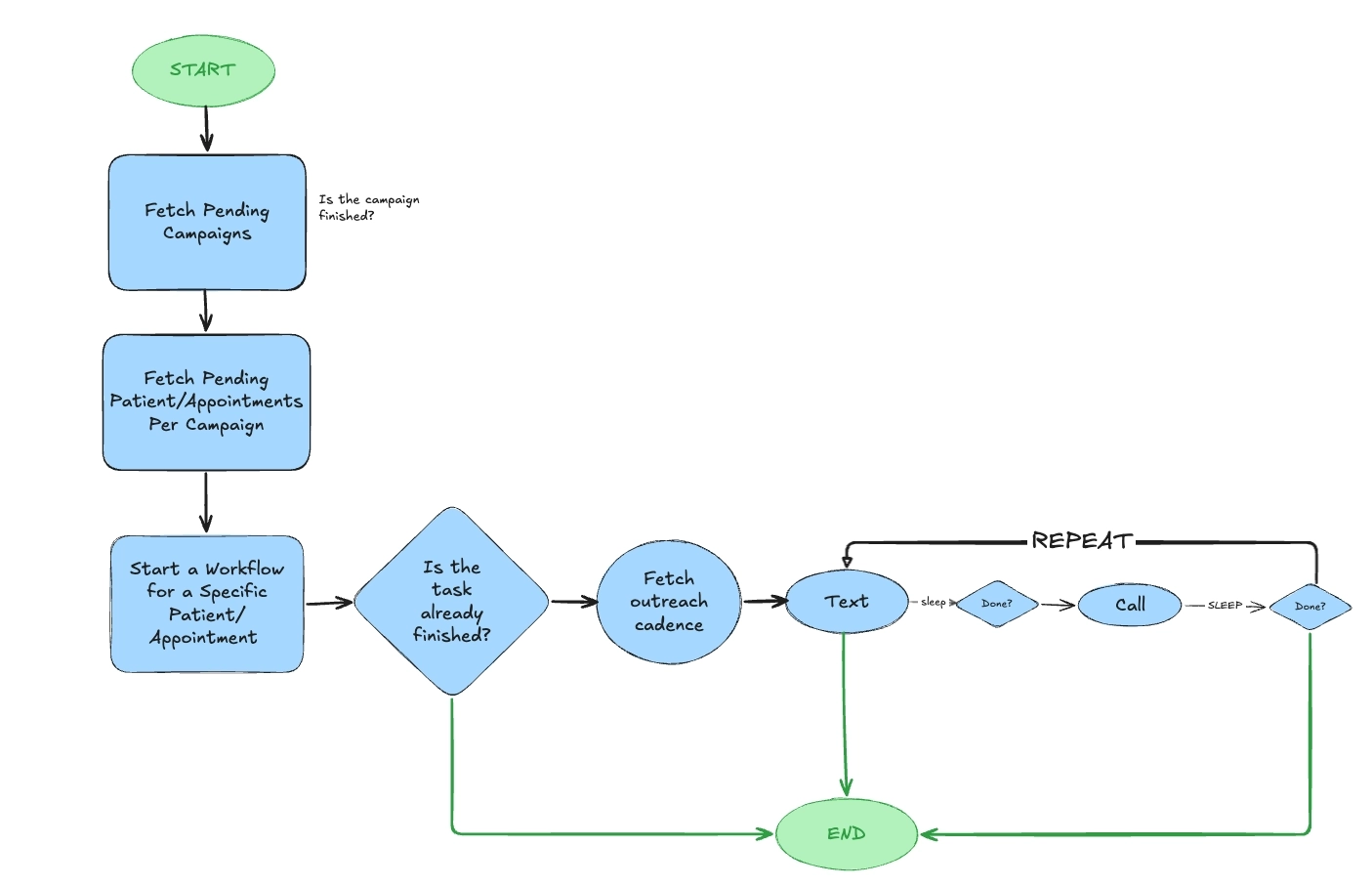
Replicating this system via software meant solving for classic challenges of long-running tasks. What happens if a pod crashes mid-workflow? What if the database goes down? How do you resume a workflow that's been running for months? We chose Temporal, a durable execution framework, because it handles all of this out of the box. Workflows survive infrastructure failures, automatically retry at configurable checkpoints, and can sleep for days or months without relying on the stability of any single process. The canonical example from Temporal's own documentation illustrates the elegance:
@workflow.defn
class SleepForDaysWorkflow:
# Send an email every 30 days, for the year
@workflow.run
async def run(self) -> None:
for i in range(12):
# Activities have built-in support for timeouts and retries!
await workflow.execute_activity(
send_email,
start_to_close_timeout=timedelta(seconds=10),
)
# Sleep for 30 days (yes, really)!
await workflow.sleep(timedelta(days=30))Sleeping for 30 days is a hard task in application side code because pods restart and scale up and down many times per day and distributing work across many workers is non trivial. Another message queue could do similar things, but it would require significant custom machinery to maintain workflow state across retries, handle checkpointing, and manage horizontal scaling. Temporal solves this beautifully right out of the box.
This durability is especially important given the realities of healthcare integrations. Anyone who has worked closely with EHR APIs knows that unexpected outages are a possibility. With Temporal it's easy to retry failed API calls from their last checkpoint rather than restarting a workflow from scratch that may have been running for months. Additionally, since Temporal workers scale horizontally, we can scale our call capacity alongside our inbound call servers, which enables us to go from one concurrent agent to a hundred in moments.
Even with Temporal's guarantees, we added additional guarantees of our own because patient outreach is so important and missing even a single call to an appointment can be catastrophic. If an EHR introduces a breaking change to their API and half of our outreach workflows fail while checking if an appointment is scheduled or not, we can't afford to have to manually identify the flows we need to restart. We added a reconciler that periodically compares pending assignments against running workflows and automatically restarts any that are missing. Combining Sentry, PagerDuty, and a Temporal interceptor, we got rapid detection of failures and automatic recovery, removing the need to backfill.
Scaling Up
With our new system in place, we needed to load test it and validate it would handle a real-world work load. We simulated a highly anticipated use case for scheduling annual flu shots for 50,000 patients. The results were initially humbling.
Originally we created each patient workflow as a child workflow.
# Limited to 2k concurrent workflows and
# they can stop the parent workflow from restarting
for assignment in assignments:
await workflow.start_child_workflow(...) We hit bottlenecks immediately. Child workflows are limited to 2,000 concurrent workflows can stop the parent workflow from restarting when something goes wrong. We scaled up the temporal worker pool, but then we quickly ran into database connection limits, trading one bottleneck for another. In order to fix this we decoupled patient workflows from the parent, launching each one as a standalone workflow with a bounded concurrency semaphore:
# Better way to start 40k+ workflows at once
async def launch_campaign_workflow(assignment_id):
await client.start_workflow(
"CampaignAssignmentWorkflow",
assignment,
id=f"campaign-assignment-{assignment_id}",
task_queue="campaign-task-queue",
)
await asyncio.gather(
*[
launch_campaign_workflow(assignment_id) for assignment_id in campaign.assignments
]
)You may also notice the start_delay, which uses a random jitter. This solved a second problem we hit soon after fixing the first. Each outbound call requires some amount of EHR API calls in order to fetch patient data and schedule appointments, so launching 50k workflows at the same time would far exceed third-party rate limits. By spreading workflow starts across the span of three hours, we could bring the throughput back in line with what our EHR integrations could handle.
Below is a chart showing our first high load campaign test
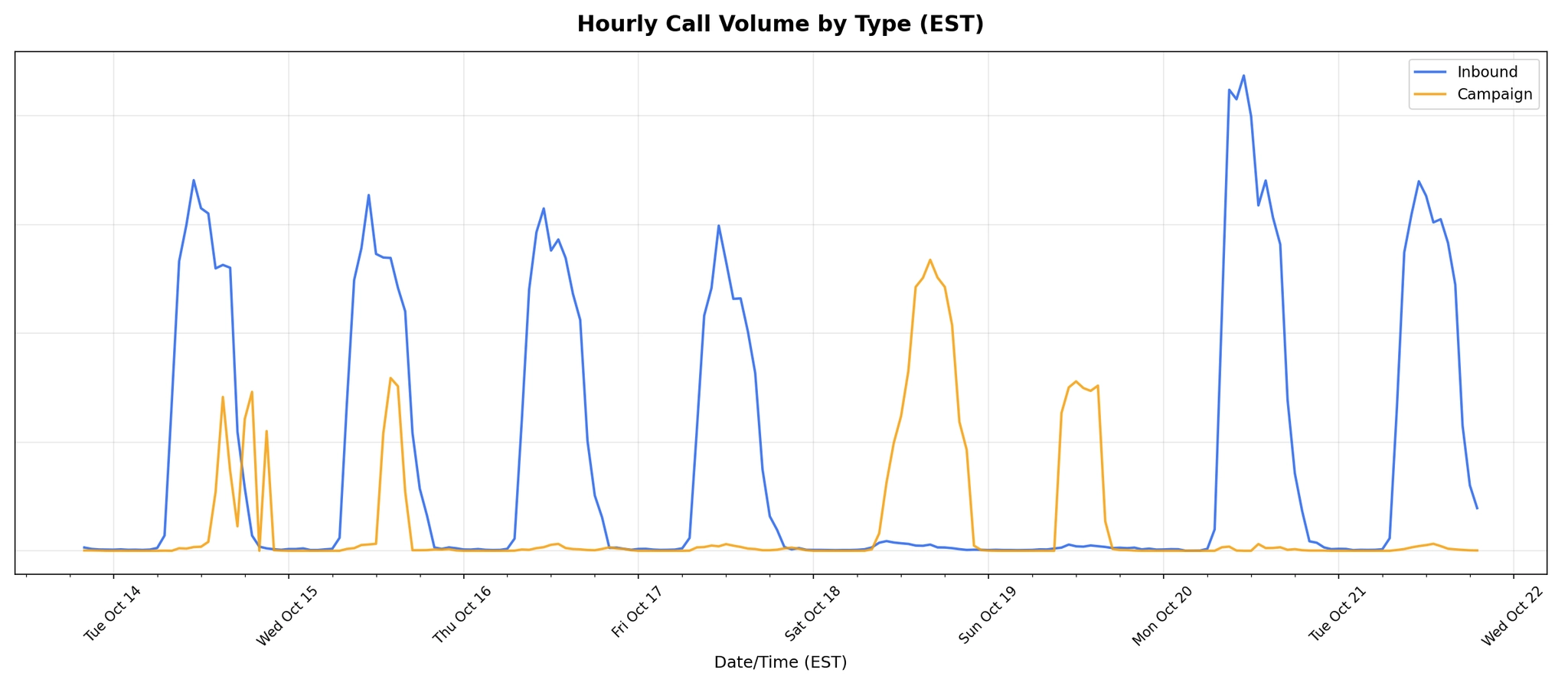
We released the system for our first high-volume flu shot campaign, starting with a smaller subset earlier in the week. Later in the week we ramped up to full volume. The result: we helped our customer triple their flu shot clinic attendance. We like to tell ourselves we saved a few lives that day 😇.
Patient Experience
Building our system to handle tens of thousands of calls didn't matter if we couldn't get patients to pick up. We learned that outbound calls face a trust problem that inbound calls do not.
One advantage of outbound patient access is that we know who we are calling. We can preload patient data and personalize the interaction from the start of the call, opening with something like
“Hey Kevin, we are calling about your appointment with Dr. William”. By establishing context immediately we can signal that this isn't spam, mitigating patients' fear of synthetic voices. While personalization helped, we noticed the biggest improvements in engagement came from interactions we scheduled before we ever made a call. Letting the patient know we would be calling them later and providing a link to take action on their own resolved close to 50% of our rescheduling outreach before we ever dialed. That quickly turned into a 90% resolution rate after we called. Verified caller ID had a significant impact as well, driving a 40% increase in call engagement compared to calls from unverified numbers.
We also learned that not all outreach is created equal. Patients with an upcoming appointment that needed to be rescheduled were far more willing to engage, as they had a concrete reason to care. Reaching out to inactive patients consistently saw lower engagement. It seems obvious in hindsight, but urgency and relevance drive pickup rates more than anything we could say in the first few seconds of a call.
Impact
Since launching Assort Activate for outbound patient interactions, we've helped customers recover thousands of appointments that would have otherwise been lost. These appointments can mean the difference between a patient getting timely care and falling through the cracks. One customer tripled their flu shot clinic attendance. Another avoided the operational chaos of a departing provider by proactively rescheduling every affected patient weeks in advance. The employee whose upcoming retirement inspired this whole effort was able to retire knowing she was leaving behind a system that would ensure her work could continue at a greater scale than she could accomplish alone.
We're still early. Every outbound campaign teaches us something new about how to reach patients, when to reach them, and what to say when they pick up. The problems ahead are as interesting as the ones we've already solved.
If these sorts of problems sound interesting to you, we're hiring.

